
New Paper on data fusion by Dimitri Prandner
Primary data collection has become increasingly challenging. There are many reasons for this: Not only has the cost of conducting face-to-face interviews increased and the number of available interviewers decreased, but the ongoing shift to web-based interviewing has resulted in shorter questionnaires, making it difficult to accurately measure latent constructs and cover a wide range of topics. Therefore, despite the advantage of conducting primary data collection to match one's research questions, secondary data analysis is often more feasible. For this purpose, data archives such as the Consortium of European Social Science Data Archives (CESSDA) provide a large amount of high-quality data. However, a common problem when working with secondary data is that important variables are missing in one dataset and are only available in another. We propose a possible solution to overcome this problem by using "data fusion", which allows to augment one dataset by including the missing variables that are initially only available in another dataset. From a statistical point of view, this corresponds to a missing value problem, which is why multiple imputation is often used to fuse datasets. Despite this promising idea, data fusion is only sporadically applied in the social sciences. This paper discusses the potential of this statistical technique in the context of social science research and derives a guide for practitioners interested in applying the method to their own research. The method and potential are discussed via an example using data from the European Social Survey (ESS) and the Austrian Social Survey (ASS).
New Paper on Open and Closed Survey Items by Jana Bernhard-Harrer and Katharina Pfaff
How we ask questions in surveys significantly impacts the answers. While previous research has examined differences between open-ended and closed-ended survey responses, our understanding remains fragmented, especially considering the growing interest in open-ended questions spurred by advances in automated text analysis. We explore how computational text analysis methods––particularly large language models––can efficiently analyze open-ended responses with promising sentiment and actor identification results, though topic classification remains more challenging. Then, we systematically compare open-ended and closed-ended responses on trust in the Austrian coalition government to assess how different formats shape the expression of political trust. We find significant discrepancies between the trust levels indicated in closed-ended questions and the trust described in open-ended responses, with paired t-tests also revealing statistically significant differences. These findings highlight that question format affects how respondents express their views, raising important considerations about the usefulness and validity of trust measures. They highlight the unique value of open-ended questions in capturing nuanced perspectives often missed by closed-ended formats. This has broader implications for survey design: including open-ended questions could enrich data quality and provide deeper insights into public opinion.
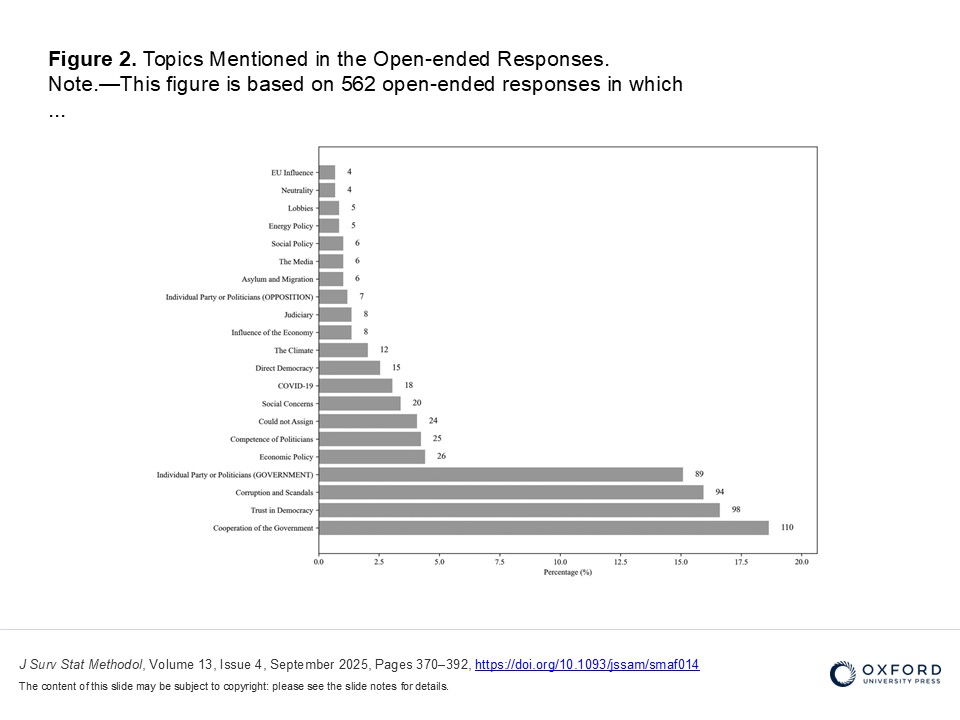
Topics Mentioned in the Open-ended Responses
Über die Veränderungen der österreichischen Umfrageforschung während der Covid-19-Pandemie von Dimitri Prandner und Alexander Seymer
Die Anzahl allgemeiner Bevölkerungsumfragen in Österreich hat seit den 1980er-Jahren kontinuierlich zugenommen und eine Dauerbeobachtung der Werte, Einstellungen und sozialen Strukutur der österreichischen Wohnbevölkerung ermöglicht. Der Beitrag geht der Frage nach, wie sich diese Umfragen in den letzten vierzig Jahren verändert haben, welche methodischen Anpassungen während der Covid-19-Krise notwendig waren und wie sie von den Forschenden wichtiger österreichischer Umfrageprogramme, u. a. dem European Social Survey, dem Sozialen Survey Österreich und der European Values Study, umgesetzt wurden. Es zeigt sich, dass in den letzten Jahren eine teilweise Abkehr von etablierten Standards wie der Zufallsstichprobe und dem persönlichen Interview stattgefunden hat, aber kein einheitliches Vorgehen erkennbar ist. Ein neuer Standard für allgemeine Bevölkerungsumfragen ist aktuell nicht zu identifizieren
Data solidarity – A White Paper. Geneva: The Lancet & Financial Times Commission on Governing Health Futures
this White paper by Barbara Prainsack, Seliem El-Sayed, Nikolaus Forgó, Łukasz Szoszkiewicz, and Philipp Baumer answers the following questions:
- What are the goals and pillars of solidarity-based data governance?
- What is data solidarity?
- How is data solidarity different from related concepts?
- What are existing legal frameworks for Data solidarity?
- What types of policy instruments are needed to complement existing laws and policies to realise and strengthen data solidarity ?
The White paper is published in The Lancet & Financial Times Commission on Governing Health Futures. Available at: https://www.governinghealthfutures2030.org/wp-content/uploads/2022/12/DataSolidarity.pdf
Blue Chips and White Collars: Whose Data Science Is It?
in their article "Blue Chips and White Collars: Whose Data Science Is It?" (Harvard Data Science Review), Seliem El-Sayed and Barbara Prainsack comment on Sabina Leonelli’s article "Data Science in Times of Pan(dem)ic" and explore how data science can be better used for the next phase of the pandemic response and the role of scientists in this process.
First, particularly during a period in which many key features of society differ from its ‘normal’ functioning, it is important to systematically collect and analyze insights into people' practices and experiences, and recognize their value for policymaking. Besides, given the increasing frequency with which results from hypothesis-free data mining are presented as actionable, it is important to be aware of the difference between correlation and causality. For example, a U.S. study cited in the commentary found that counties with higher home values were correlated with higher mortality rates, that is, deaths associated with COVID-19. The authors of the study can only speculate about the reasons for this correlation. It thus becomes apparent that policymakers should resist the pressure to act quickly until the results from hypothesis-free data mining have been supplemented with causal models. Finally, how technologies affect different groups in society should be carefully studied to avoid reinforcing existing inequities related to access to technology and wealth.
The authors conclude that scientists must recognize that they are not merely conducting neutral analyses. By choosing a framing of the central problem of a research project, scientists also determine and limit the form of a possible solution. For example, if researchers attribute a low willingness to get vaccinated to a lack of information, a 'solution' to that problem is likely to be concerned with closing this information gap. This 'solution' would overlook the fact that a low willingness to get vaccinated may reflect more than people's attitudes towards vaccination - it may, for example, indicate a lack of trust in policy makers or a general sense of insecurity. The pandemic, in which the pressure to base policy on scientific evidence is particularly high, places a greater obligation on scientists to reflect on the norms, goals, and values that research articulates and promotes.
Paper on Topic Modeling by Jana Bernhard, Martin Teuffenbach, Hajo Boomgaarden
Topic Modeling is currently one of the most widely employed unsupervised text-as-data techniques in the field of communication science. While researchers increasingly recognize the importance of validating topic models and given the prevalence of discussions of inadequate validation practices in the literature, there is limited understanding of the consequences of employing different validation strategies when evaluating topic models. This study applies two different methods for topic modeling to the same text corpus. It uses four validation strategies to assess how the choice of validation method affects the final model selection and evaluation. Our findings indicate that different approaches and methods lead to different model choices and evaluations, which is problematic. This might lead to unwanted results in case the choice of model has a decisive impact on findings and, consequently, on theory development and practical implications.

Paper by Jana Bernhard, Martin Teuffenbach & Hajo G. Boomgaarden3
Topic Modeling is currently one of the most widely employed unsupervised text-as-data techniques in the field of communication science. While researchers increasingly recognize the importance of validating topic models and given the prevalence of discussions of inadequate validation practices in the literature, there is limited understanding of the consequences of employing different validation strategies when evaluating topic models. This study applies two different methods for topic modeling to the same text corpus. It uses four validation strategies to assess how the choice of validation method affects the final model selection and evaluation. Our findings indicate that different approaches and methods lead to different model choices and evaluations, which is problematic. This might lead to unwanted results in case the choice of model has a decisive impact on findings and, consequently, on theory development and practical implications.
Editorial: Big data and machine learning in sociology
Dimitri Prandner (AP5) hat gemeinsam mit Heinz Leitgöb und Tobias Wolbring ein "Thinkpiece" zum Thema Big Data & Sociology herausgegeben. Die Digitalisierung der Gesellschaft bringt einige Herausforderungen für die empirischen Sozialwissenschaften mit sich. Der Text bietet einen interessanten Überblick mit Fokus auf Big Data und Machine Learning, sowie einen tieferen Einblick in die epistemologische Perspektive (Section 2), die Datenperspektive (Section 3) und die Perspektive der Datenanalyse (Section 4).
Hier finden Sie den Text, der in 'Frontiers in Sociology' veröffentlicht wurde.

Open Educational Ressources - Seltene, aber wichtige Implusgeber für die Digitalisierung der Lehre?
In AP5 wurde im letzten Jahr die Lage von deutschsprachigen offen zugänglichen Methodenlehrinhalten analysiert. AP5-Leiter Dimitri Prandner und Mitarbeiter Matthias Forstner präsentieren die Ergebnisse in Journal "Frontiers in Education" und auf der HEAd'22 Konferenz.
Einen Einblick in das Datenset und Code-Beispiele kann man auf Zenodo finden:
- ZENODO | Overview: GERMAN LANGUAGE OER FOR SOCIAL SCIENCE METHODS EDUCATION (https://zenodo.org/record/6603205#.YvYKYPjP3dk)
Die Ergebnisse können Sie hier nachlesen.
Beitrag über Digitize! in Zeitschrift für Hochschulentwicklung
Die Projektpartner*innen aus allen Arbeitspaketen von Digitize! haben einen Beitrag über Digitize! geschrieben, der die Erfolge und lessons learned zur Halbzeit der Projektlaufzeit sehr gut im Überblick darstellt. Die Ergebnisse werden aus Sicht der Sozialwissenschaften, aus Sicht der Data Science, aus ethischer sowie aus juristischer Sicht beschrieben.
Hier finden Sie den Beitrag, der im November in der Zeitschrift für Hochschulentwicklung (Sonderheft 'Digitalisierung in der Forschung - Projekte österreichischer Hochschulen 202-2024') veröffentlicht wurde.

Weitere Publikationen:
- Barbara Prainsack, Seliem El-Sayed, Nikolaus Forgó, Łukasz Szoszkiewicz, and Philipp Baumer (2022). Data solidarity: a blueprint for governing health futures. The Lancet: Digital Health 4/11: E773--E774. https://www.thelancet.com/journals/landig/article/PIIS2589-7500
- Barbara Prainsack and Nikolaus Forgó (2022). Why paying individual people for their data is a bad idea. Nature Medicine 28: 1989-1991. https://www.nature.com/articles/s41591-022-01955-4